keepalived
keepalived的作用就是解决单点问题,当其中一个调度器宕机另一个备用的调度器取而代之,从而实现高可用。keepalived有两个节点,一个为活动节点Active和备份节点Passive。在lvs集群上实现高可用需要有vip,ipvs规则,使用nginx集群实现高可用需要vip和nginx服务。
vip在某个时刻只能在一个节点上,当一个节点宕机了另外一个节点必须取得vip并配置再自己的主机上才能作为访问入口。那么怎么样才能知道活动节点宕机了呢?主节点定时发送组播信息及heartbeat心跳信息,各个主机时间要同步,二者之间约定当主节点宕机后备用调度器就将IP抢过来配置再自己的主机上。对高可用集群来讲,节点之间所征用的资源主要在两个方面,IP和存储。在存储上如nfs可解决并发存储问题。
lvs:vip,ipvs rules
nginx:vip,nginx service
VRRP协议:
vrrp:virtual route redundent protocol,虚拟路由冗余协议。 keepalived就是vrrp协议在linux主机上的以守护进程的实现,能够根据配置文件自动生成ipvs规则,能够对RS做健康状态监测。
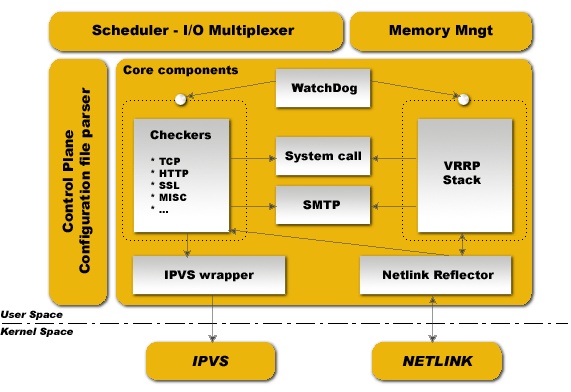
Scheduler:调度器
Memory Mngt:内存管理
Control Plance Configuration Parser:配置文件分析器的主控工具,能够reload配置文件,类似Nginx 的master进程。
Core components:核心组件,包括VRRP Strack,也就是vrrp协议的实现。Checkers检测功能。checkers是一个线程,VRRP Stack也是一个线程。
IPVS wrapper:就是能够根据配置文件生成规则的组件。
Watch Dog:内部自我救赎的高可用机制,自动监控VRRP进程是否正常,如果进程挂掉就会把它重新启动起来。
配置文件
安装keepalived:
CentOS 6.4版本以后keepalived已近被收录发行版,可以直接使用yum install keepalived。
主配置文件位置:/etc/keepalived/keepalived.conf
服务启动脚本:/etc/sysconfig/keepalived
配置文件的组成部分:
GLOBAL CONFIGURATION 全局配置段
VRRPD CONFIGURATION vrrp守护进程
vrrp instance 虚拟路由器
vrrp synchoinzation group
LVS CONFIGURATION
HA Cluster配置前提:
1、要能够使用主机名与对方主机进行通讯,本机的主机名与hosts中定义的主机保存一致,要与hostname(uname -n)获得的名称保持一致,修改主机名的命令有:在6中修改文件/etc/sysconfig/network,在7中hostnamectl set-hostname HOSTNAME。各个节点要能够互相解析主机名。一般通过hosts文件解析。
2、各节点时间同步。
3、确保iptables端口开放及关闭selinux。
配置文件中的 global_defs{} 配置段是全局配置,vrrp_instance{} 是用来做虚拟路由实例的。
切换到 /etc/keepalived/keepalived.conf 先将配置文件备份,然后将所有的 virtual_server{} 配置段注释,因为此时用不到。
全局配置:
global_defs {
notification_email { #当服务器故障发送邮件到这些邮箱
acassen@firewall.loc
failover@firewall.loc
sysadmin@firewall.loc
}
notification_email_from Alexandre.Cassen@firewall.loc #发送这些邮件使用的账户
smtp_server 192.168.200.1 #邮件服务的服务器器地址
smtp_connect_timeout 30 #如果发送邮件有问题,这里定义超时时间
router_id LVS_DEVEL #标识物理设备的唯一标识
vrrp_skip_check_adv_addr
vrrp_strict
vrrp_garp_interval 0
vrrp_gna_interval 0
}虚拟路由配置:
vrrp_instance VI_1 { #这个名字不要一样
state MASTER #初始状态,MASTER和BACKUP
interface ens33 #IP地址配置再那个网卡上
virtual_router_id 51 #虚拟路由的ID, 工作在同一个虚拟路由上的这个ID要相同。
priority 100 #0-255,优先级,要想成为MASTER就要定义高的优先级
advert_int 1 #心跳信息的发送间隔
authentication { #认证信息
auth_type PASS #认证方式为简单字符认证
auth_pass 1111 #认证用的字符串,同一个虚拟机实例上要一样
}
virtual_ipaddress { #虚拟IP地址,这个地址将会配置再上面设置的 interface 上。
192.168.200.16
192.168.200.17
192.168.200.18/24 dev eth2 label eth2:1 #这个配置方法只能在Centos6上,在7上只能用IP/mask方式。
}
nopreempt #非抢占模式,默认抢占模式
}开启日志:
在 /etc/sysconfig/keepalived 修改该为: KEEPALIVED_OPTIONS="-D -S 3"
在 /etc/rsyslog.conf 中在下面添加 local3.* /var/log/keepalived.log,然后重启日子服务systemctl restart rsyslog.service。
这些修改在每个虚拟路由上都要修改,这个日子功能不影响keepalived的正常工作,不开启也可以。这个日子记录了keepalived的心跳信息,启动关闭等等信息。
手动将主节点将为备用节点:
在配置文件中加上这一段脚本,这个脚本的作用是每隔一段时间执行一次,当检测到有down文件时就将此节点的权重减2,从而实现将主节点降低为备用节点,只要在响应目录中添加上down文件就可以控制此操作。
vrrp_script chk_schedown{
script "[[ -f /etc/keepalived/own ]] && exit 1 || exit 0"
interval 2 #每隔多长时间检测一次
weight -2 #减少的权重
} 下面这个脚本作用和上面的一样,如果上面的配置不行,实现不了就用下面这个。
vrrp_script hand_down {
script "/etc/keepalived/run.sh" #这里放着一个shell脚本,注意权限问题
interval 1
weight -2
}
run.sh
#!/bin/bash
if [ -f /etc/keepalived/down ]; then
exit 1
else
exit 0
fi这段脚本和其他的配置段是平级的,不存在包含关系。上面只是定义脚本,还没有去调用,调用脚本需要在 vrrp_instance 中定义,定义格式如下,track_script 是用来监控脚本的,track_interface 是用来监控端口的。
vrrp_instance VI_1 {
........
track_script {
chk_schedown
}
}配置完成后重启keepalived,然后在 /etc/keepalived/ 下创建 down文件就可以将某个路由降级为备用节点。
基于LVS实现高可用的配置方法:
基于LVS的nat模式下实现高可用需要有vip和dip,且是可动的,dip是调度器与后端集群通讯的ip,vip是客户端请求的ip,当vip变动时,dip也要vip跟着变动,也就是说vip和dip必须同时在一个调度器上。
vrrp_svnc_group VG_1{
group {
VI_1 #name of vrrp_instance (below)
VI_2 #one for each moveable IP
}
}
vrrp_instance VI_1 {
eth0
vip
}
vrrp_instance VI_1 {
eth0
dip
}两遍都出现VIP现象:
这种情况是两个主机通讯问题造成的,关闭防火墙或设置响应的规则即可解决。
双主模式
一本情况下两个调度器只有一个是正常工作的,还有一个就会处于闲置状态,这样会造成资源浪费,如果把两个调度器都使用起来呢,首先要将域名解析到两个IP上,这样访问者会被分流到两个IP上,两个调度器上正常工作时各自配置一个IP,也是VIP,当其中一个调度器宕机就将另一个作为备用节点,也就是两个vip在一个主机上。
配置过程:
将每个主机上的 keepalived 都配置两个 vrrp_instance ,且如下配置都是不一样的。
state 一个为主的MASTER,一个为备用的BACKUP。
virtual_router_id 虚拟路由ID,同一组要一样,因为这是不同的两组,所以要不一样。
priority 优先级,抢占模式各自的主节点要比备用的优先级高。
virtual_ipaddress 使用的vip也要不一样。
两个主机的配置是一样的模式,注意双主模式不要限定组播地址 vrrp_mcast_group4 这样会导致只有一组生效,因为默认不同的组的组播地址是不一样的。
global_defs {
notification_email {
root@localhost
}
notification_email_from keepalived@localhost
smtp_server 127.0.0.1
smtp_connect_timeout 30
router_id node1.zhuqiyang.com
}
vrrp_script chk_schedown {
script "/etc/keepalived/run.sh"
interval 2
weight -2
}
vrrp_instance VI_1 {
state BACKUP
interface ens33
virtual_router_id 51
priority 99
advert_int 1
authentication {
auth_type PASS
auth_pass fa2a8dae
}
virtual_ipaddress {
192.168.96.139/24
}
track_script {
chk_schedown
}
}实例配置:
这是其中一个的配置,另一个配置根据上面的条件做响应修改即可。
#这是双主模型,单组下面这个不加即可。
vrrp_instance VI_2 {
state MASTER
interface ens33
virtual_router_id 61
priority 100
advert_int 1
authentication {
auth_type PASS
auth_pass fa2a8saex
}
virtual_ipaddress {
192.168.96.140/24
}
track_script {
chk_schedown
}
}通过脚本发送通知
当主机状态改变时,需要发送信息通知给管理员,keepalived可以通过写脚本的方式发送邮件。具体配置为在实例vrrp_instance 中配置如下内容,每个实例都要配置响应的脚本内容。
vrrp_instance VI_1 {
.......
notify_master "/etc/keepalived/test.sh master"
notify_backup "/etc/keepalived/test.sh backup"
notify_fault "/etc/keepalived/notify.sh fault"
}
这个notify.sh的内容如下,也可以自定义内容。
#!/bin/bash
vip=192.168.96.139
contact='root@localhost'
notify() {
mailsubject="`hostname` to be $1: $vip floating"
mailbody="`date '+%F %H:%M:%S'`: vrrp transition, `hostname` changed to be $1"
echo $mailbody | mail -s "$mailsubject" $contact
}
case "$1" in
master)
notify master
# /etc/rc.d/init.d/haproxy start
exit 0
;;
backup)
notify backup
# /etc/rc.d/init.d/haproxy stop
exit 0
;;
fault)
notify fault
# /etc/rc.d/init.d/haproxy stop
exit 0
;;
*)
echo 'Usage: `basename $0` {master|backup|fault}'
exit 1
;;
esacnginx高可用集群
先配置后端的服务器集群,每台主机上都安装好httpd服务,然后再在两个调度器上分别安装上nginx,再配置 upstream ,然后再在location中配置proxy_pass 。
upstream webservers {
server 192.168.96.128:80 weight=1;
server 192.168.96.130:80 weight=1;
}上面这个upstream 配置在 http{} 内即可。
location / {
proxy_pass http://webservers/;
} 这个location 配置在 server{} 中。
后端的集群主机中在各自的主页写上不一样的内容以便调试区分。这些工作完成后就可以在开启 keepalived 服务了,然后访问vip就可以看到负载均衡的高可用服务了。
nginx宕机处理:
当nginx意外宕机但是 keepalived 依然运行,虽然这时候已近不能提供服务但是vip任然在当前的主机上,这时候应该将当前主机的keepalived降权为备用主机,让正常服务的nginx主机作为调度器。实现这个功能就是将 vrrp_script { } 中设置为检测nginx主机是否服务正常,如果不正常则将主机降权为备用节点,然后设置 track_script { } 去跟踪设置的脚本即可。
在chk_nginx.sh脚本中的内容如下,就是检测nginx服务是否正常。
#!/bin/bash killall -0 nginx &> /dev/null exit $?
下面这个是追踪脚本chk_nginx的设置。
track_script {
chk_nginx
} 设置完成后重启keepalived服务,然后将nginx停止服务,看备用节点是否将vip抢过去了。
一般情况下如果nginx宕机了需要将nginx修复上线,如果修复不了就备用节点成为主节点,当nginx宕机了如何修复呢,可以在notify的触发事件中重启nginx服务。只要在触发的脚本中添加重启nginx服务的命令即可。
#!/bin/bash
vip=192.168.96.139
contact='root@localhost'
notify() {
mailsubject="`hostname` to be $1: $vip floating"
mailbody="`date '+%F %H:%M:%S'`: vrrp transition, `hostname` changed to be $1"
echo $mailbody | mail -s "$mailsubject" $contact
}
case "$1" in
master)
notify master
systemctl restart nginx.service
exit 0
;;
backup)
notify backup
systemctl restart nginx.service
exit 0
;;
fault)
notify fault
# /etc/rc.d/init.d/haproxy stop
exit 0
;;
*)
echo 'Usage: `basename $0` {master|backup|fault}'
exit 1
;;
esac双主模式高可用集群:
双主模型(active/active)高可用集群的实现就是创建两个vrrp实例,其中一个为主另一个则为备用,这样两台调度器就可以同时进行工作了,利用域名解析将域名解析到两个vip,一个配置实例如下,红色的表示不一样的地方。
! Configuration File for keepalived
global_defs {
notification_email {
root@localhost
}
notification_email_from root@localhost
smtp_server 127.0.0.1
smtp_connect_timeout 30
router_id node4.zhuqiyang.com
}
vrrp_script hand_down {
script "/etc/keepalived/run.sh"
interval 1
weight -2
}
vrrp_script chk_nginx { # 这个脚本检测要先定义然后才能在下面引用,否者不生效
script "/etc/keepalived/chk_nginx.sh"
interval 1
weight -2
}
vrrp_instance VI_1 {
state MASTER
interface ens33
virtual_router_id 51
priority 100
advert_int 1
authentication {
auth_type PASS
auth_pass fa2a8dae
}
virtual_ipaddress {
192.168.96.139/24 dev ens33 label ens33:0
}
track_script {
chk_nginx
}
notify_master "/etc/keepalived/notify.sh master"
notify_backup "/etc/keepalived/notify.sh backup"
notify_fault "/etc/keepalived/notify.sh fault"
}
vrrp_instance VI_2 {
state BACKUP
interface ens33
virtual_router_id 61
priority 99
advert_int 1
authentication {
auth_type PASS
auth_pass fa2av8da9
}
virtual_ipaddress {
192.168.96.140/24 dev ens33 label ens33:1
}
track_script {
chk_nginx
}
notify_master "/etc/keepalived/notify.sh master"
notify_backup "/etc/keepalived/notify.sh backup"
notify_fault "/etc/keepalived/notify.sh fault"
} 配置完成后尝试着将其中一个调度器的nginx服务关闭,在另一个调度器上查看是两个vip是否已经配置上,然后在启动停掉的nginx服务,再看看vip是否被抢回来,两个vip分别配置在两个调度器上。
快速配置
快速使用配置:
! Configuration File for keepalived
global_defs {
notification_email {
acassen@firewall.loc
failover@firewall.loc
sysadmin@firewall.loc
}
notification_email_from Alexandre.Cassen@firewall.loc
smtp_server 192.168.200.1
smtp_connect_timeout 30
router_id k1 # 主机名
vrrp_skip_check_adv_addr
#vrrp_strict # 遵守严格的VRRP协议,不支持单播,否者会添加DROP的iptables规则
vrrp_garp_interval 0
vrrp_gna_interval 0
script_user root # 运行检测脚本的用户
enable_script_security # 运行检测脚本的用户要加
}
vrrp_script check_port { # 这个脚本检测要先定义后使用,否者不生效
script "/etc/keepalived/check_port.sh" # 注意给这个脚本赋于执行权限
interval 2 # 检测时间间隔
weight -20 # 检测失败后对权重的操作
}
vrrp_instance VI_1 {
state MASTER # 节点状态,必须大写 可选值:MASTER|BACKUP
interface eth0
virtual_router_id 51 # 相同集群id要一样
priority 100 # 节点优先级
advert_int 1
authentication {
auth_type PASS
auth_pass 123456 # 同一个集群密码要一样
}
virtual_ipaddress { # 虚拟地址
192.168.199.95/24 dev eth0 label eth0:0
}
track_script { # 引用检测脚本
check_port
}
}参数说明:
! Configuration File for keepalived
global_defs { #全局定义部分
notification_email { #设置报警邮件地址,可设置多个
acassen@firewall.loc #接收通知的邮件地址
}
notification_email_from test0@163.com #设置 发送邮件通知的地址
smtp_server smtp.163.com #设置 smtp server 地址,可是ip或域名.可选端口号 (默认25)
smtp_connect_timeout 30 #设置 连接 smtp server的超时时间
router_id LVS_DEVEL #主机标识,用于邮件通知
vrrp_skip_check_adv_addr
vrrp_strict #严格执行VRRP协议规范,此模式不支持节点单播
vrrp_garp_interval 0
vrrp_gna_interval 0
script_user keepalived_script #指定运行脚本的用户名和组。默认使用用户的默认组。如未指定,默认为keepalived_script 用户,如无此用户,则使用root
enable_script_security #如果路径为非root可写,不要配置脚本为root用户执行。
}
vrrp_instance VI_1 { #vrrp 实例部分定义,VI_1自定义名称
state MASTER #指定 keepalived 的角色,必须大写 可选值:MASTER|BACKUP
interface ens33 #网卡设置,lvs需要绑定在网卡上,realserver绑定在回环口。区别:lvs对访问为外,realserver为内不易暴露本机信息
virtual_router_id 51 #虚拟路由标识,是一个数字,同一个vrrp 实例使用唯一的标识,MASTER和BACKUP 的 同一个 vrrp_instance 下 这个标识必须保持一致
priority 100 #定义优先级,数字越大,优先级越高。
advert_int 1 #设定 MASTER 与 BACKUP 负载均衡之间同步检查的时间间隔,单位为秒,两个节点设置必须一样
authentication { #设置验证类型和密码,两个节点必须一致
auth_type PASS
auth_pass 1111
}
virtual_ipaddress { #设置虚拟IP地址,可以设置多个虚拟IP地址,每行一个
192.168.119.130
}
track_script { #脚本监控状态
chk_nginx_service #可加权重,但会覆盖声明的脚本权重值。chk_nginx_service weight -20
}
notify_master "/etc/keepalived/start_haproxy.sh start" #当前节点成为master时,通知脚本执行任务
notify_backup "/etc/keepalived/start_haproxy.sh stop" #当前节点成为backup时,通知脚本执行任务
notify_fault "/etc/keepalived/start_haproxy.sh stop" #当当前节点出现故障,执行的任务;
}
virtual_server 192.168.119.130 80 { #定义RealServer对应的VIP及服务端口,IP和端口之间用空格隔开
delay_loop 6 #每隔6秒查询realserver状态
lb_algo rr #后端调试算法(load balancing algorithm)
lb_kind DR #LVS调度类型NAT/DR/TUN
#persistence_timeout 60 同一IP的连接60秒内被分配到同一台realserver
protocol TCP #用TCP协议检查realserver状态
real_server 192.168.119.120 80 {
weight 1 #权重,最大越高,lvs就越优先访问
TCP_CHECK { #keepalived的健康检查方式HTTP_GET | SSL_GET | TCP_CHECK | SMTP_CHECK | MISC
connect_timeout 10 #10秒无响应超时
retry 3 #重连次数3次
delay_before_retry 3 #重连间隔时间
connect_port 80 #健康检查realserver的端口
}
}
}不抢回vip:
vrrp_instance VI_1 {
state MASTER
interface eth0
virtual_router_id 51
priority 100
advert_int 1
nopreempt # 不抢回VIP
authentication {
auth_type PASS
auth_pass 123456
}
virtual_ipaddress {
192.168.199.95/24 dev eth0 label eth0:0
}
}